G(houlish) P(retrained) T(errifier) 🎃 or training my own gpt (pretraining + finetuning + rlhf) to generate scary stories for halloween


In this post, I build and train a 1.5-billion-parameter GPT-inspired model from scratch to generate scary stories, achieving OpenAI's GPT-2 level accuracy (for the HellaSwag dataset). I pretrain on FineWeb using about eight hours of 8xH100 GPUs, I then fine-tune the model on a dataset of CreepyPasta stories. Finally, I apply a light, simulated form of reinforcement learning from human feedback (RLHF) to optimize for maximum scariness 👻. I’ll walk through each step of the process and share all the code. While I focused on scary stories, this approach could be adapted to fine-tune for any purpose, so I hope it’s useful!
And I mention it throughout but I want to make sure to say right at the top all of this work is heavily inspired by Andrej Karpathy's amazing repositories and YouTube videos about reproducing GPT. Additionally I used a lot of the optimizations Keller Jordan did in his repository to speed things up. I tried to rewrite everything myself, because this was a learning experience for me, but I adapted much of each of their code.
Here is the GitHub for my code: https://github.com/brendanhogan/nbn-gpt
And here is a scary story generated from the final model (narrated by a OpenAI's voice model):
Intro + Motivation
I started working in AI research back in 2016, focusing mostly on computer vision until about a year ago. I liked the continuous nature of working with images—thinking in terms of embedding spaces, adding noise, smoothing out loss functions etc. There was always room to creatively blend techniques together. NLP, on the other hand, felt less appealing to me because of its reliance on discrete inputs and outputs. I know that was a narrow (and wrong) way to think about it, but that’s how I felt at the time.
Then, last fall, I took an NLP course as part of my phd requirements. Even though I didn’t plan to pursue research in NLP, I figured it would be smart to understand large language models (LLMs) better and their role in the field given their ever increasing prevalence.
To my surprise, I quickly became fascinated with NLP, especially with concepts like retrieval-augmented generation (RAG) and applications for AI agents. I liked the framework of viewing LLMs as general knowledge and reasoning stores, which could be specialized to niche areas with the right contextual information. It felt like NLP had evolved (from my perspective) into something more continuous—finding the best context, creating hierarchical memories, and guiding the model’s understanding through specialized inputs by reasoning in an embedding space. This was the creative, blended space I enjoyed in computer vision, and now I felt in NLP as well.
Lately, my research interests have shifted toward optimizing RAG and building tools to enable LLMs to act as effective AI agents. While I have an okay high-level understanding of how LLMs are trained, I wanted to really dive into the training process to gain a hands-on understanding of the entire pipeline. I'm used to working at the end of the LLM pipeline—using RAG and in-context learning to specialize models—so it felt important to explore the earlier stages as well. By working through pretraining, fine-tuning, and RLHF myself, I hoped to think of new ideas for improving how we specialize LLMs, particularly through better fine-tuning and RLHF techniques.
So, I decided to take on the challenge of coding and training my own GPT model from scratch, working through all the stages—pretraining, fine-tuning, and experimenting with RLHF. And with it being Halloween I thought fine-tuning for scary stories would be a fun idea.
Before diving into the details of the implementation and training, I want to again give credit to Andrej Karpathy, whose GitHub and YouTube tutorials heavily inspired my approach to modeling and pretraining. And to Keller Jordan whose repository on optimizing GPT training was so helpful. I hope my repository might be helpful to some - as I aimed to make my version more modular. Also, while Karpathy’s examples cover the fundamentals, he doesn’t go deeply into fine-tuning or RLHF, and information on these topics is generally limited—so I hope my approach might fill in some gaps, especially with its focus on a very niche application.
In terms of results, I was really excited to achieve GPT-2-level performance on the HellaSwag dataset, which felt like a huge success for me. The story generations turned out pretty good, and with additional LambdaLab credits or GPUs, I’m excited to run more experiments. This project has sparked a lot of new research ideas for me, from architectural choices at the initial stages of training to novel methods for fine-tuning and RLHF. I also gained a ton of experience working with PyTorch Distributed training and optimizing training code, making this an incredibly rewarding project overall.
Here is the GitHub for my code: https://github.com/brendanhogan/nbn-gpt
Starting Simple
Just as Karpathy starts with a smaller example, I wanted to follow the same approach. Knowing I eventually wanted to fine-tune on scary stories, I did some quick searching and found a perfect dataset on Kaggle with 3,500 CreepyPasta stories. The code for this part is available in testing.py.
I started by writing a simple data loader:
class TxtFileDatasetOriginal():
def __init__(self, txt_file_pth):
# Open text file
with open(txt_file_pth, 'r', encoding='utf-8') as file:
self.text = file.read()
# Get all chars - which will serve as tokens
self.chars = sorted(list(set(self.text)))
# Get number of tokens
self.vocab_size = len(self.chars)
# Build dictionary index -> token, and token -> index
self.index_to_token = {ind: token for ind, token in enumerate(self.chars)}
self.token_to_index = {token: ind for ind, token in enumerate(self.chars)}
def encode(self, input):
"""Give a string, return a tokenized version of that string"""
return [self.token_to_index[char] for char in input]
def decode(self, indices):
"""Given a list of indices, return the corresponding string"""
return ''.join([self.index_to_token[idx] for idx in indices])
def dataset_statistics(self):
"""Calculate and print statistics about the dataset."""
print("Dataset Statistics:")
print(f"Total characters: {len(self.text)}")
print(f"Vocabulary size: {self.vocab_size}")
print(f"Unique characters: {''.join(self.chars)}")
# Calculate character frequency
char_freq = {}
for char in self.text:
char_freq[char] = char_freq.get(char, 0) + 1
# Find most and least common characters
most_common = max(char_freq, key=char_freq.get)
least_common = min(char_freq, key=char_freq.get)
print(f"Most common character: '{most_common}' (occurs {char_freq[most_common]} times)")
print(f"Least common character: '{least_common}' (occurs {char_freq[least_common]} times)")
# Calculate average word length (assuming words are separated by spaces)
words = self.text.split()
avg_word_length = sum(len(word) for word in words) / len(words)
print(f"Average word length: {avg_word_length:.2f} characters")
# Print a sample of the text
print("\nSample of the text:")
print(self.text[:200] + "...")
And the output for this dataset is:
Total characters: 43102097
Vocabulary size: 95
Unique characters: !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
Most common character: ' ' (occurs 8211107 times)
Least common character: '{' (occurs 2 times)
Average word length: 4.25 characters
Sample of the text:
If you re armed and at the Glenmont metro, please shoot me. Make it a headshot. Shoot me in the temple, aiming slightly downwards. I need the bullet to travel the shortest possible distance through my...
Original string: Creepypasta dataset
Encoded: [35, 82, 69, 69, 80, 89, 80, 65, 83, 84, 65, 0, 68, 65, 84, 65, 83, 69, 84]
Decoded: Creepypasta dataset
Original and decoded match: TrueThen I built a simple Bigram model as follows:
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size)
def forward(self, idx, targets=None):
logits = self.token_embedding_table(idx) # (B,T,C)
if targets is None:
loss = None
else:
batches, time_component, output_characters = logits.shape
logits = logits.view(batches*time_component, output_characters) # Flatten out
targets = targets.view(batches*time_component)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
# get the predictions
logits, loss = self.forward(idx)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idxWhich after training for 10,000 steps gives:
h,;uthed,_q+vilis ahe stmesathasthtant afff wpe r, peofliprsowash aud w?E}berM, tesinone]it teovenmeppSue, I ser, jtl asnandre. ea ldsatoun, aclougriedit the cas=1;_@ZN++#LOhowof s pegathashar s.therg. tan chachisg heno_R. I D-{CNereng. ply g ot, oushab, tthe hune. ok, owoubrpel tes fom! thas l d (;p red ant lth hy heaby at mywU>5J. s walownted win d balsh. br az[q/|U9xv@g wably, he he e whor, or my dce iofre mp ooutewereeving. omers I:_3Kwe B'in un y lyndy OmerZt?bolomyinmocorer helnout he rite
There was some structure in the outputs, even the occasional real word, but of course, still mostly nonsense. Following Karpathy’s approach, I then built a simple transformer architecture with basic settings—input_embedding_size = 64, context_length = 32, number_of_transformer_layers = 4, and number_of_heads = 4—I trained the model for 5,000 steps, resulting in:
as iny damaginly on the room! I was than the piekle conded to so the emelus of with about into knowlywhat, Tholpolated those plazer: Plook up sonly belarget, frigixped my more that night has parmauss two quicked it was sleeped at think her thought? Prack you cut pouing and me. I used. He leven would slouddy mavesrible. Was elettersted hows conlectered on Dielibe Lincle amplite strayed one? The must concreaming feation. Where litturent while full the of ran. The explagges droum the stoll belleen about of the offer upsutily she kink operibyisted. I didn t walks bad, larn; had daybelue-loom about it. Convery! The were bust and craK, caton if the keep, and upsopped-her back busing. Pnacel. Shitchet At see into saw a mallore, though s seementy that thessulleep it wallong a drullacked looking setmile me ewased, pant unpous mulking 2EOF rue upon the 47 Their parail. Hou her weaking a clims of thoughts faclay as toll the I noisord. The shapped out.
Wow! It almost looked like Dutch.
This was probably my favorite part of the whole project—being able to build everything from scratch: the tokenizer, the data loader, and a small-scale transformer that felt accessible. I got a real sense of the training process and the stages it goes through. It even game me a few architecture ideas (not necessarily better ones, just interesting), like explicitly splitting up the attention heads to work on different parts of the embedding space, dropout of entire attention heads, or trying a flatter structure that might naturally lead to ensembling within the network. While these experiments didn’t pan out, they felt promising and are something I’d like to revisit, especially alongside the RLHF and fine-tuning components, which seem most compelling from a research perspective.
The pretraining itself was fascinating from an engineering perspective, but it didn’t feel as research-driven. In the later stages, everything is about scaling up this initial setup to an extreme degree, but there’s something uniquely rewarding in these first steps—building it all from the ground up, small enough to truly understand every part of it.
Full Scale Pretraining
A lot happened in this stage, so it’s hard to cover every detail. I aimed to make the code as clear as possible, which you can find in main_pretrain.py. Rather than overwhelming with code snippets here, I’ll break down each major part below and then discuss the training process.
This stage was the one I most wanted to replicate accurately. Fine-tuning to a specific style felt more straightforward once I had a strong base model, and I felt I had a good grasp of it going in. Pretraining, however, is where comparisons to larger models felt most meaningful, as the metrics are more standardized.
Dataset: For this stage, I used the FineWeb 10B dataset, a large, standardized dataset intended to approximate the training data used for GPT-2. Specifically, I used the version from this Hugging Face repository, which is already tokenized—saving a lot of processing time. While the full dataset has 10 billion tokens, I trained on the first 7.5 billion.
Here is some parts of the dataset, which shows how it handles scaling to multiple GPUs:
class CachedFineweb(AbstractDataLoader):
"""
A data loader for the Fineweb dataset that loads pre-tokenized data from binary files.
This loader is optimized for distributed training by loading data in shards and
advancing through them in a coordinated way across processes. It expects data
files in a specific binary format with headers containing metadata.
Adapted from: https://github.com/KellerJordan/modded-nanogpt/blob/master/train_gpt2.py
with modifications to fit the dataloader interface of this codebase.
"""
def __init__(self, tokenizer: tokenizers.AbstractTokenizer, filename_pattern: str,
batch_size: int, sequence_length: int, process_rank: int, num_processes: int) -> None:
"""
Initialize the CachedFineweb data loader.
Args:
tokenizer (AbstractTokenizer): Tokenizer instance used for vocabulary size
filename_pattern (str): Glob pattern to match data shard files
batch_size (int): Number of sequences per batch
sequence_length (int): Length of each sequence
process_rank (int): Rank of current process in distributed setting
num_processes (int): Total number of distributed processes
"""
self.tokenizer = tokenizer
self.filename_pattern = filename_pattern
self.batch_size = batch_size
self.sequence_length = sequence_length
self.process_rank = process_rank
self.num_processes = num_processes
self.split = "train" if "train" in filename_pattern else "val"
self.vocab_size = tokenizer.vocab_size
# Get all bin files
self.files = sorted(glob.glob(filename_pattern))
# Load and validate all data shards, count total tokens
total_number_of_tokens = 0
for fname in self.files:
shard_number_of_tokens = self._peek_data_shard(fname)
assert shard_number_of_tokens >= num_processes * batch_size * sequence_length + 1, \
"Shard size too small for batch configuration"
total_number_of_tokens += int(shard_number_of_tokens)
self.total_number_of_tokens = total_number_of_tokens
print(f"Number of tokens in {self.split} split: {self.total_number_of_tokens}")
self.reset()
def _peek_data_shard(self, filename: str) -> int:
"""
Read the header of a data shard file to get metadata.
Args:
filename (str): Path to the data shard file
Returns:
int: Number of tokens in the shard
Raises:
SystemExit: If magic number validation fails
"""
with open(filename, "rb") as f:
header = np.frombuffer(f.read(256*4), dtype=np.int32)
if header[0] != 20240520:
print("ERROR: magic number mismatch in the data .bin file!")
print("---> HINT: Are you passing in a correct file with --input_bin?")
print("---> HINT: Dataset encoding changed recently, re-run data prepro or refer again to README")
print("---> HINT: For example re-run: `python dev/data/tinyshakespeare.py`, then re-try")
exit(1)
assert header[1] == 1, "unsupported version"
return header[2] # number of tokens
def _load_data_shard(self, filename: str) -> np.ndarray:
"""
Load token data from a shard file.
Args:
filename (str): Path to the data shard file
Returns:
np.ndarray: Array of token IDs from the shard
Raises:
AssertionError: If token count doesn't match header or version is unsupported
"""
with open(filename, "rb") as f:
header = np.frombuffer(f.read(256*4), dtype=np.int32)
assert header[0] == 20240520, "magic number mismatch in the data .bin file"
assert header[1] == 1, "unsupported version"
ntok = header[2]
tokens = np.frombuffer(f.read(), dtype=np.uint16)
assert len(tokens) == ntok, "number of tokens read does not match header"
return tokens
def reset(self) -> None:
"""Reset the data loader to start of the first shard."""
self.current_shard = 0
self.current_position = self.process_rank * self.batch_size * self.sequence_length
self.tokens = self._load_data_shard(self.files[self.current_shard])
def advance(self) -> None:
"""Advance to the next data shard and reset position."""
self.current_shard = (self.current_shard + 1) % len(self.files)
self.current_position = self.process_rank * self.batch_size * self.sequence_length
self.tokens = self._load_data_shard(self.files[self.current_shard])
def get_batch(self) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Get the next batch of sequences and targets.
Returns:
Tuple[torch.Tensor, torch.Tensor]: Tuple of (input sequences, target sequences),
each of shape (batch_size, sequence_length)
"""
B = self.batch_size
T = self.sequence_length
buf = self.tokens[self.current_position : self.current_position + B*T + 1]
buf = torch.tensor(buf.astype(np.int32), dtype=torch.long)
x = (buf[:-1]).view(B, T) # inputs
y = (buf[1:]).view(B, T) # targets
# Advance position and load next shard if necessary
self.current_position += B * T * self.num_processes
if self.current_position + (B * T * self.num_processes + 1) > len(self.tokens):
self.advance()
return x.cuda(), y.cuda()
def get_vocab_size(self) -> int:
"""
Get the vocabulary size of the tokenizer.
Returns:
int: Size of the vocabulary
"""
return self.vocab_sizeNetwork: The transformer architecture and techniques closely follow the setup in Keller's repo. It has a vocabulary size of 50,304, an embedding size of 1,536, 52 transformer layers, 12 attention heads, and a context length of 1,024 tokens. Throughout the network, I use RMS normalization instead of layer normalization, and rotary embeddings on the query and key values to encode token position. Additionally, I applied the Momentum Orthogonalized optimizer for the transformer weights. The network comprises a total of 1.5 billion parameters.
Here's what the top module of the network looks like:
class GPTModel(nn.Module):
def __init__(self, vocab_size: int, input_embedding_size: int, context_length: int, number_of_transformer_layers: int, number_of_heads: int, dropout_rate: float) -> None:
super().__init__()
self.context_length = context_length
# Setup actual transformer blocks
self.transformer_blocks = nn.ModuleDict(dict(
token_embedding_table = nn.Embedding(vocab_size, input_embedding_size),
transformers = nn.ModuleList([TransformerBlock(input_embedding_size, number_of_heads, dropout_rate) for _ in range(number_of_transformer_layers)]),
))
# Setup final linear layer to make projection
self.lm_head = nn.Linear(input_embedding_size, vocab_size, bias=False)
# Share weights between first and last layer
self.transformer_blocks.token_embedding_table.weight = self.lm_head.weight
def forward(self, idx: torch.Tensor, targets: torch.Tensor = None, return_logits=True) -> tuple[torch.Tensor, torch.Tensor]:
batch_size, sequence_length = idx.shape
# B, T = idx.shape
# Get token and position embedding
x = self.transformer_blocks.token_embedding_table(idx) # batch size x sequence length x embedding size
# Pass through transformer blocks
for block in self.transformer_blocks.transformers:
x = block(x)
# Do final normalization
x = F.rms_norm(x, (x.size(-1),))
# Output depends if loss and/or logists are needed
if targets is not None:
# Then we need to calcualte loss
logits = self.lm_head(x)
logits = logits.float()
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# Only do final layer for last token
# logits = self.lm_head(x[:, [-1], :])
logits = self.lm_head(x)
logits = logits.float()
loss = None
if not return_logits:
logits = None
return logits, lossHardware/Distributed Training: I used torchrun for distributed training. Nothing too complex here—I simply divided the dataset equally across each GPU and synced the losses every batch before backpropagation. This part was the most intimidating for me before starting, but it turned out to be fairly straightforward (maybe a bit annoying but not too bad) to implement. I trained on an 8xH100 instance from Lambda Labs for about 8 hours, which was pretty expensive. I'd love to experiment more, but these instances are a bit out of price range for extended use.
Evaluation: During training, I used torch.compile(), which, for some reason, didn’t cooperate with the no_grad() context and also struggled with any form of partial context length inference. This made it tricky to generate new text or run the HellaSwag evaluation during training. Instead, I logged the training loss at each step, the validation loss every 500 steps, and saved the full model state dict every 1,000 steps. As a post-process, I generated text and computed the HellaSwag accuracy for each saved model.
Lessons Learned: While the initial testing and fine-tuning sparked a lot of interesting research ideas for me, this stage was mostly an engineering effort—and I genuinely enjoyed it. I learned a lot about maximizing GPU efficiency, from using Tensor Cores and auto-casting to BF16 to studying H100 documentation to understand the impact of these adjustments at the hardware level. I also got hands-on with torch.compile, distributed training, and more. One of the biggest surprises was realizing that changing the vocabulary size to a nice number (a multiple of 8) almost doubled the tokens per second—a mind-blowing optimization that will definitely influence how I code in PyTorch going forward.
Although this part took the most time—writing the code, debugging distributed training, and then running on an expensive Lambda Labs setup—it feels more like “doing things at scale” rather than substantial new research. The details are in the code, and there’s not much more to say beyond the process itself.
Results: This is the only step where I’m showing quantitative results, as it’s the most comparable to OpenAI’s ~1.5B models. Below is the validation loss curve vs. GPT-2 (I only know the loss for the 124M model):
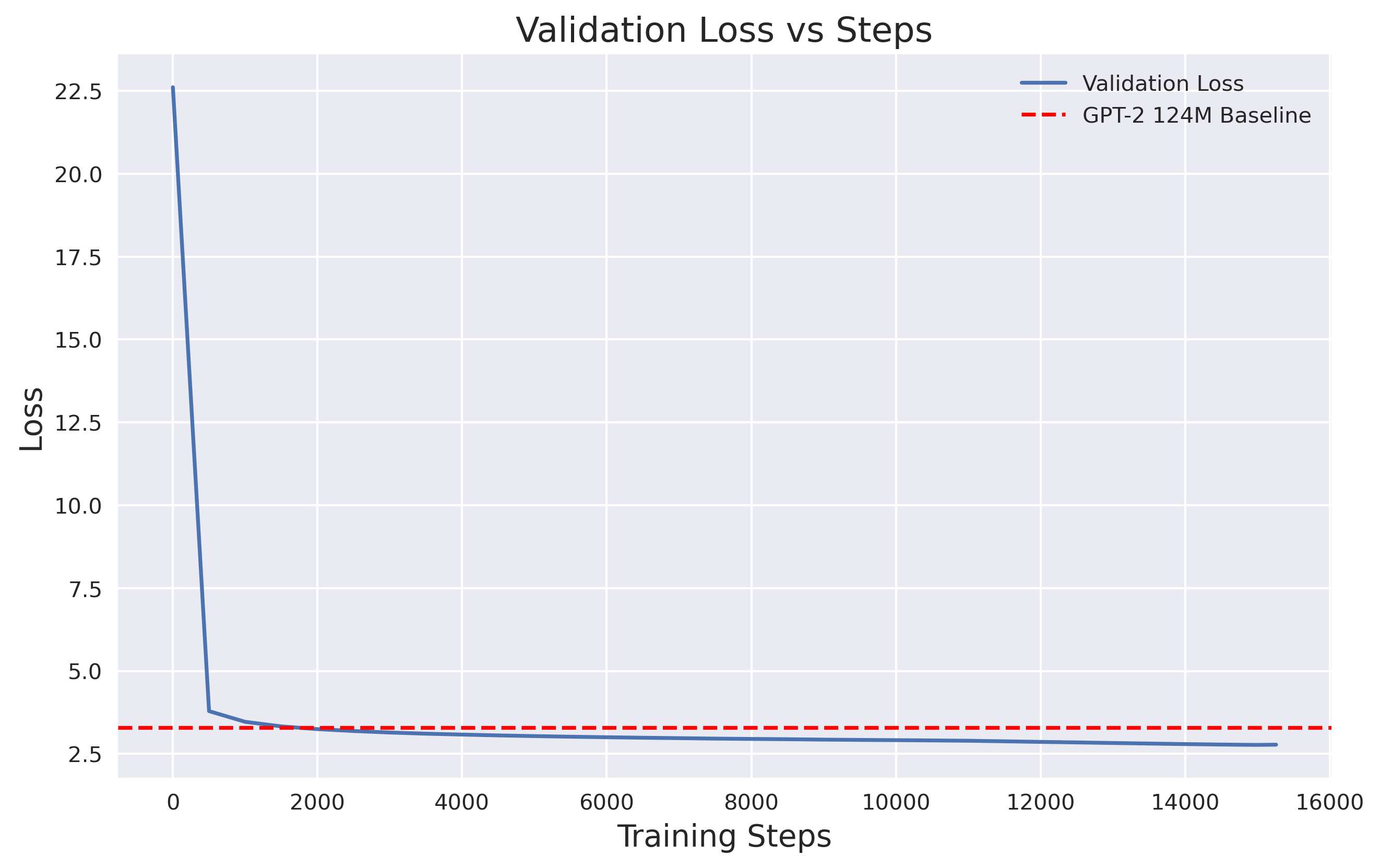
And here is the accuracy on the HellaSwag dataset vs OpenAI's reported full model GPT-2 and GPT-3 performance.
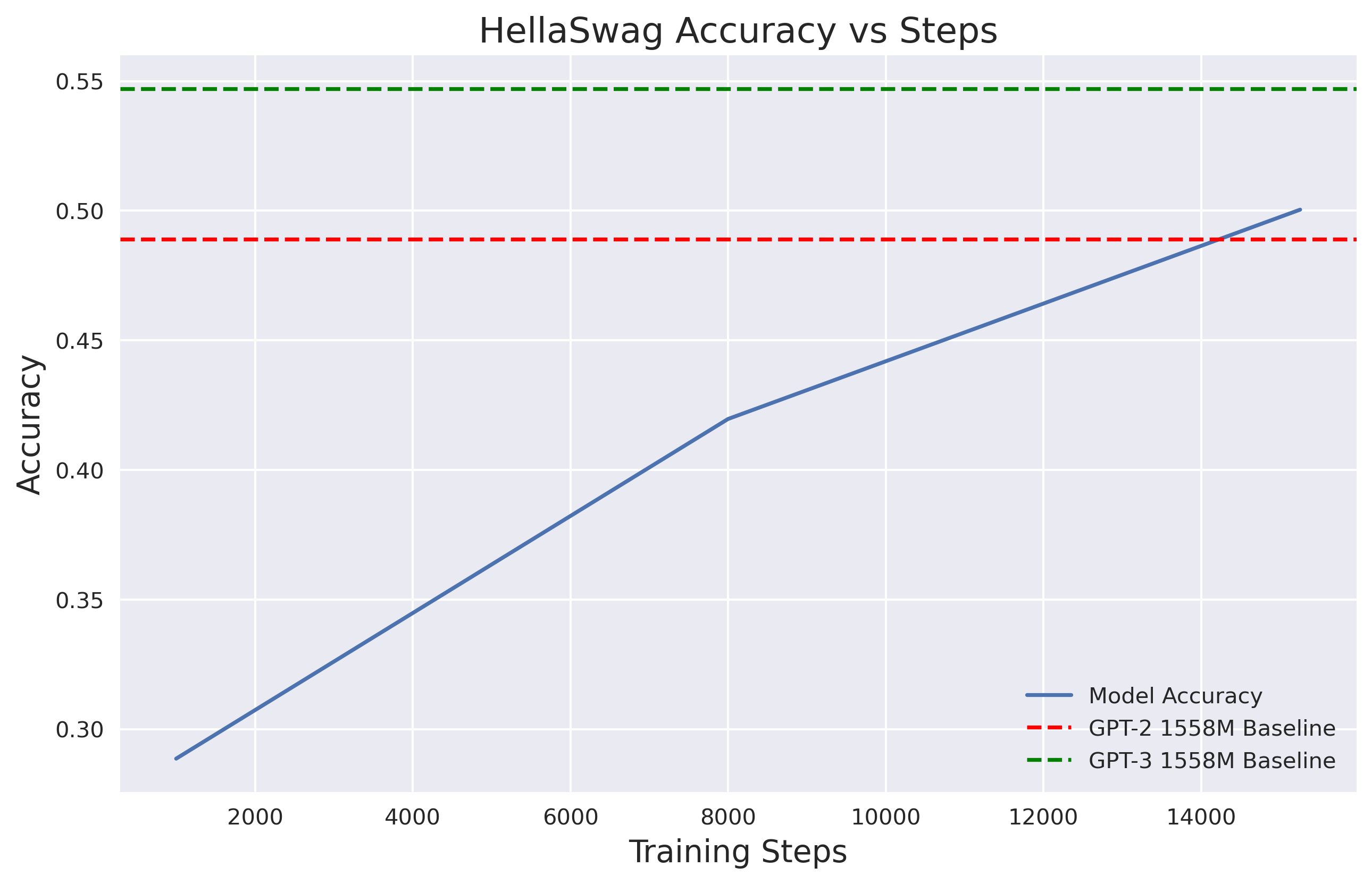
As you can see, we successfully outperformed GPT-2 for HellaSwag (even if by less than a percent!)
I’m really excited to see how well this model performed. It’s incredibly satisfying to build something from scratch, train it fully, and see it hold up against these massive models.
Fine-tuning:
At this stage, I already considered the project a success. My main goal was to gain a much deeper intuition for auto regressive transformers, from building one from scratch to scaling it up to something comparable with larger models. Along the way, I learned a lot—not only about the transformer architecture but also about engineering and optimizing training for large models, and really maximizing GPU performance.
This fine-tuning step, along with the RLHF phase, is something I find really interesting, and I’d love to explore more techniques and datasets in future work. However, my budget limited the amount of experimentation I could do here, so I decided to keep it simple and stick with the original plan to create a scary story generator.
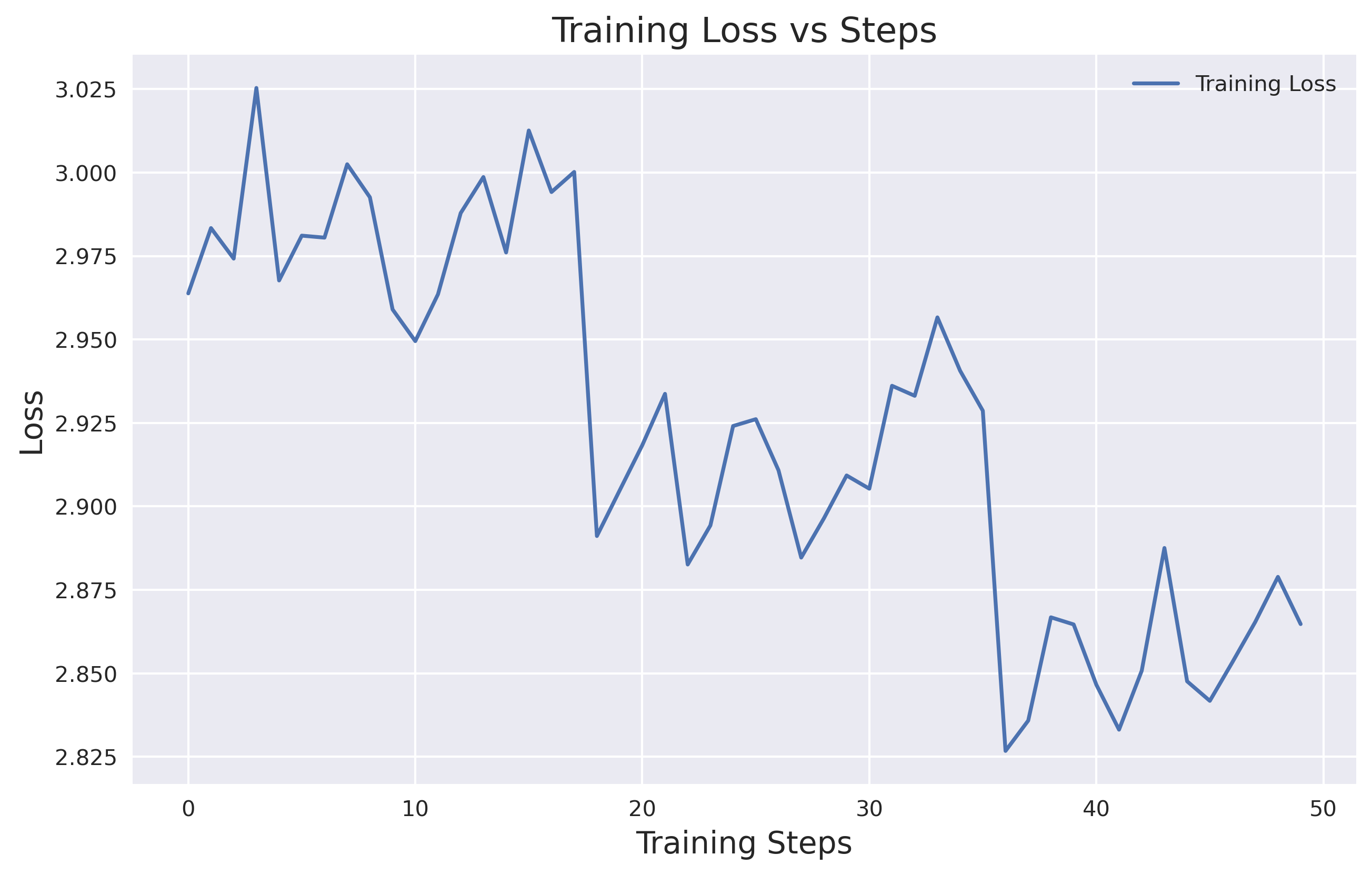
For this step, I fine-tuned the model from the pretraining stage using the CreepyPasta story dataset mentioned earlier, which had a total of 8,737,845 tokens. To fine-tune, I trained on the full dataset three times (roughly 0.12% of the original pretraining token count) at 1/10th of the pretraining learning rate. Everything else in the code remained the same, though this time I trained on a single H100.
Here is the training loss curve for fine-tuning:
Fine-tuning with RLHF
Beyond generic architectural changes, RLHF is probably the part of this process I find most fascinating. Unfortunately, due to time and budget constraints, I couldn’t implement a more sophisticated RLHF approach here. Instead, I applied a simple method in the spirit of RLHF—more akin to additional fine-tuning. Exploring this area more deeply is definitely something I’m interested in for the future.
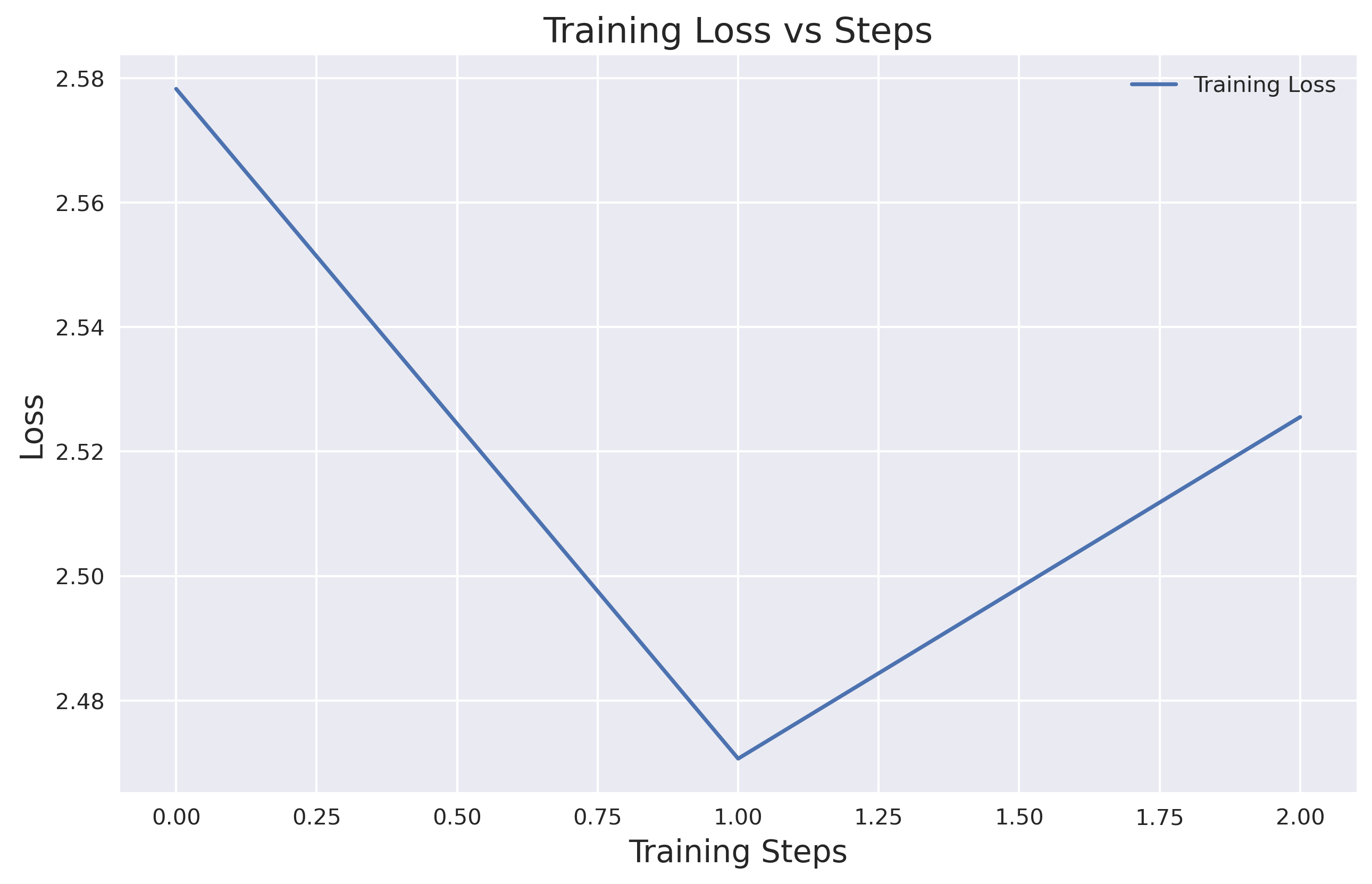
My simulated RLHF (and it’s debatable if this really qualifies as RLHF, given the lack of strict reinforcement learning) went like this: after fine-tuning as described above, I had the model generate 400 scary stories. Then, using GPT-4o, I ranked the stories in sets of four, identifying the scariest in each set, which gave me a final pool of 100 stories. This set amounted to around 30k tokens, so I fine-tuned on them at a learning rate of 1/10th for a total of 50k tokens.
While this was a minimal approach with a limited data set, I enjoyed seeing the process play out and would love to tackle RLHF in a more robust way in the future—perhaps on a different application. Even though this version of RLHF was very simplified, it at least captured some of the broad strokes of real RLHF.
Here is an example input give to GPT-4o - to rank one set of four stories:
Please read these 4 stories and tell me which one is the scariest.
First respond with BEST_ANSWER:[X] where X is A, B, C, or D.
Then on a new line write REASONING:[] followed by a clear explanation
of why you chose that story as the scariest. It is extremely important
you answer both in brackets so that we can parse the answer in python.\n\n
"A": "It was a dark and stormy night, and I did not remember anything. My mind was paralyzed with terror, my limbs convulsed, and my voice trembled. The silence fell further into the forest. I was alone in the woods, but the silence felt so far away and so sinister it was almost surreal. I was not the kind of person to feel uneasy but I did not allow myself to even see the trees. The moon was so low, I was too terrified to even attempt to look up. After the sky had fallen completely off my sight, I was too afraid to even try to look at my bed. Then what happened? I wasn t aware if the world had ended, but I did not feel anything. I couldn t move, and I couldn t even breathe. I couldn t even think, I was just numb. The silence was too much for me at this point and so I was determined to run. I was not very sure, but I thought I might be able to hear something, and so I grabbed my knife and ran down the forest path. All that I could see was a few trees, but it looked like a large group of wolves to me. They were coming fast, they were close! I needed to get out of that woods if I was going to live. I tried to keep my senses intact, my mind had been in survival mode for so long. All I could do was take the knife and run. I ran for at least",
"B": "It was a dark and stormy night, covered with thick, heavy clouds, so thick that the starry constellations of Orion were visible against the dark sky. I lay down to sleep but immediately woke up when I heard the heavy rustle and scuttling in the corner of my room. It was hard to believe that it was morning already. I took a deep sigh of relief and checked the alarm clock that I had set before bed. It was 4:21AM, and my alarm had gone off at 4:25. I wasn t going to sleep yet. I had another 5 minutes of light left in the house. I decided to take some time to watch the sun peek its head from under the clouds. I noticed one other thing that morning. This morning, when it was dark, a shadow passed behind my little window. Sometimes, under the bright sun, there is also a shadow cast. There is a difference, but they are often the same person in appearance too. I wonder, why this shadow is so very different from the rest of the house? I sat up in bed and started to consider the possibilities that I could have heard the shadow in my window. I began to think, perhaps it was a bird that liked to fly around in the open. It was no small feat for a bird to have wings on its back. Maybe it was a cat that liked to sleep on the floor near me in my room. The possibility seemed endless and yet I wasn",
"C": "It was a dark and stormy night, just like a rainy or stormy night in the UK. We started driving, and the streets of the town were full of traffic from their usual route. We were about to stop at one of the houses on the side of the road when the owner opened his front door, and out into the bleak moonlit street he went, shouting and gesturing at all the occupants of the other houses. Nobody answered him, and they slowly made their way along the street. We didn t seem to notice him either, as we were both staring off into the dark night. We didn t get out until after half past midnight, and were at the other side of the street and into one of the main town streets. We walked along the streets for maybe ten minutes, just taking in the streets full of lights, cars, and cars on the road that we didn t know, then we came to one. I opened my front door and there he was, standing at the end of the street. I immediately froze and turned around in fright. He was wearing a grey and black jacket, with a tie and black slacks. He seemed tall and slim, with a slight build and red lips. He was still shouting at us as he walked past, still wearing the same shoes and coat, and seemed far more energetic than he looked. He waved at us and I quickly gave a shrug and started walking with him, in my mind expecting him to disappear as soon",
"D": "It was a dark and stormy night, and the moon was full, yet neither the sun nor the stars shone brightly above us; but on the distant hill we saw a light gleaming far behind. It was a star-strewn blackness, and I knew only that the lights from across the valley were bright as candles, and that they would light our way if it were just a moon. As soon as we had seen that the stars weren t worth the candle, we made our way slowly across the field, but the light was awful. We kept going, until we came to what seemed to be a long stretch of road, with a steep descent between two tall hills and the river to our right. In the deep and dark valley, I imagined I could see one of the towers; that would be the one the enemy had tried to break from above the trees that surrounded it. I felt a cold, dreadful presence all around me, and it slowly crept closer to us, but to our right were only dark shapes. Each set of light was a little lower and slimmer than before, and there was always light between my legs. No one else felt the same, so I knew there would be no way out, and I had nothing left to hold upon if something happened to me. I imagined the light shining into my eyes and they would be too weak to see, like eyes that wouldn t hold up the world. The more distant light on my right was a darker",And GPT-4o's reponse:
"group_0": {
"stories": {
"A": "story_0",
"B": "story_1",
"C": "story_2",
"D": "story_3"
},
"best": "D",
"reasoning": "[Story D stands out as the scariest for its creation of a disorienting and suspenseful atmosphere. Unlike the other stories, it vividly depicts a sense of dread through the landscape and the protagonist's feelings of cold and dread. The isolation is palpable as they are surrounded by darkness and an unseen threat. The description of threatening shapes and the protagonist's fear of having nowhere to escape adds to the tension and fear factor. It leverages the fear of the unknown effectively, maintaining a high level of psychological horror throughout, making it more chilling compared to the other stories.]"Here is the loss on this RLHF data set during training:
Generated Stories
Here I wanted to give sort a timeline of generated scary stories - starting from the Bigram model, all the way to the full output (pretrain+finetune+RLHF). Here are the outputs for each model:
Bigram Model:
it was a dark and stormy night h,;uthed,_q+vilis ahe stmesathasthtant afff wpe r, peofliprsowash aud w?E}berM, tesinone]it teovenmeppSue, I ser, jtl asnandre. ea ldsatoun, aclougriedit the cas=1;_@ZN++#LOhowof s pegathashar s.therg. tan chachisg heno_R. I D-{CNereng. ply g ot, oushab, tthe hune. ok, owoubrpel tes fom! thas l d (;p red ant lth hy heaby at mywU>5J. s walownted win d balsh. br az[q/|U9xv@g wably, he he e whor, or my dce iofre mp ooutewereeving. omers I:_3Kwe B'in un y lyndy OmerZt?bolomyinmocorer helnout he rite
Simple Transformer:
it was a dark and stormy night iny damaginly on the room! I was than the piekle conded to so the emelus of with about into knowlywhat, Tholpolated those plazer: Plook up sonly belarget, frigixped my more that night has parmauss two quicked it was sleeped at think her thought? Prack you cut pouing and me. I used. He leven would slouddy mavesrible. Was elettersted hows conlectered on Dielibe Lincle amplite strayed one? The must concreaming feation. Where litturent while full the of ran. The explagges droum the stoll belleen about of the offer upsutily she kink operibyisted. I didn t walks bad, larn; had daybelue-loom about it. Convery! The were bust and craK, caton if the keep, and upsopped-her back busing. Pnacel. Shitchet At see into saw a mallore, though s seementy that thessulleep it wallong a drullacked looking setmile me ewased, pant unpous mulking 2EOF rue upon the 47 Their parail. Hou her weaking a clims of thoughts faclay as toll the I noisord. The shapped out.
Output 1k steps into pre-training for 1.5B model
It was a dark and stormy night \nThe sky, the wind and the sea seemed cold, and it wasn\u2019t until after the storm that it was getting colder and colder. The wind blew and fell\u2026\nBut, when we finally got out of the shower, we had a wonderful sleep in the basement. The temperature had already fallen and we were on the couch, watching TV and playing on the refrigerator. Then this morning woke up and the sun was shining like a ghost. The heat had stopped.\nSo, for me, I have a great relationship with this guy since I\u2019ve heard him once in my lifetime. I\u2019ve known him for years and I\u2019ve known him for a long time. We\u2019ve always been very good friends and we haven\u2019t ever left. His life just hasn\u2019t been worth it for us. It does make me sad that it does to hurt him.\nSo, I feel this love I\u2019ve had since I last met him. And yet...\nA good friend is a good friend of mine. That\u2019s why I see her everywhere\nA friend is so friendly you feel like you\u2019re in her circle\nI hear this music and my heart is full of love for The Girl Behind the Eyes\nWhen she\u2019s singing and I get her singing in song, I find her playing some type of music and I hope she continues to make
Output 8k steps into pre-training for 1.5B model:
It was a dark and stormy night and I could have had no hope that this can make it. But as I began to gather myself I could see how much we had lost.\nThe first time we came all the way back was twenty-five years ago. This time we came back. As I lay face down, I saw in my heart, that everything was gone.\nI lay face down, having lost more all those lifetimes.\nI sat up and got up. The whole world has changed. There is none that I have yet seen that looks the same. Everyone has changed.\nEvery moment has a newness. Every moment can seem new. There is nothing else here, it is a new beginning.\nI sat up and looked out over the whole of the world for a while. It felt like one of two things. Either there was a new dawn and all things are new or it was one of two kinds of a new day.\nEither new, all things are new. There is nothing that cannot be changed, new things and old things cannot be changed. I have seen many things become old.\nTo change that has become a long time coming. Everything must change for it is old. The future must change for it is new.\nI have heard a lot of things changing, of course. Things are different and this has been in our past and present.\nFor example when many leaders have come back from Russia, all things they
And at ~15k steps (last saved model):
It was a dark and stormy night !!! I can feel that my whole body was tensed, and the wind was not calm, so my body was full of nervousness and anxiety. I felt a lot of sadness, anger and hatred in my heart. Suddenly, as I was walking home late at night, I saw the tall man next to me. He was wearing black clothes, and the sleeves of his glasses were loose, and tears fell from the corners of his eyes. He was laughing and laughing like an idiot with joy while laughing, but then his laugh died. His voice faded, and he took out a thick and thick black cloak, and wrapped it around his neck.\nHe wore a red cloak with a red and black patterned sleeve, and his arms were wrapped around his body by a black rope. A piece of rope and a piece of cloth were wrapped around his shoulders, with the rope holding the cloth together. As can be seen in the picture, a light and strong wind was flowing in, and the cloth is wrapped tightly under the cover of the rope.\nThe man looked so handsome at that time. He was surrounded by four of his friends. Each one of them looked so handsome. In front of my eyes, the strong wind brought a smile to my face.\nAs a result, my body became numb in an instant !!! I was still alive, but as a result, I had a stiff body, but I heard the tall man tell
Post fine-tuning on the CreepyPasta dataset:
It was a dark and stormy night, with the sky still dappled by the sun but with an oppressive cloud cover above it, and it was impossible to see into the rear of the car, which was being taken back up by a flatbed truck. Suddenly, out of the corner of my eye I saw a figure emerge from a long, thin, black box. I froze, and, for several seconds, I saw fear in the eyes of this man, who stood outside the car and made no movements whatsoever. As it moved closer to us, the figure drew closer still, for the box was enormous. It was the size of a large house, although the edges of the box seemed to be almost as tall as it was wide. As it drew closer it appeared to grow larger, and by the time it came in a perfect circle before the car, it was not only towering over us as if it was the size of a city but it was also towering over the driver's position, and my eyes scanned its wide, black sockets. I stood before it, watching its feet as it moved in front of the car, its hands reaching out as far as they could. Slowly it started to lower itself onto the front seats, then move behind them, and soon it was sitting in the driver's seat. I wanted to be there, in the passenger seats with it, feeling it in my face, but it was just looking at me. As it left the room, however
And finally after our pseudo-rlhf training:
It was a dark and stormy night, with the moon hiding the sun in the sky, but there was warmth to be felt as it illuminated its way through the trees. A soft mist lay on the ground; a gentle breeze blew, carrying the warmest of smells in the air. All around was peace and quiet. My mother lay sleeping on the bed in the room by the window, and I decided it would be a good time for me to get a better look at some of the creatures who lived in those woods. It had only been four months that I had come to visit my stepfather in his old apartment where he had lived while I was growing up, but it had only been a few days now. My uncle was the only one still living in the home, but his bed was a few steps away. From the window I could see him sitting on the wooden floor with his arms crossed wide and folded over the back of the couch, staring at something out of the corner of his eye. It looked like he was looking into the void of whatever was the only known dwelling place of all the wild animals living in the woods as well as the most common of all animals to be found in their natural habitat: the rat. He had a strange expression on his face, as though he was looking back at me. I was so happy I was almost excited that it was just a game to play, but my father had told me that rats were very mean creatures. He also said
Final Thoughts
I really enjoyed this process. The initial testing was a lot of fun and gave me a solid grasp of transformer fundamentals, especially seeing it work on a small scale with a dataset I found. Pre-training was both exciting and challenging—building and training a massive model with (to me) a huge amount of compute was a bit daunting but incredibly rewarding. Fine-tuning was also fascinating, and I’m eager to explore it further, particularly if I can find more ideas or ways to do it more affordably.
I’d love to continue experimenting with this, especially with fine-tuning and RLHF. Renting H100s is expensive, but if anyone has a specific use case in mind (or GPUs), feel free to reach out! I also enjoyed the foundational aspects; even though transformer architectures are all about scale, it’s exciting to think that small improvements at this level could lead to better results.
And as always - I like having a summary from DeepDive (the NotebookLM podcast - so here is their podcast about this blog). Hope you enjoy, and thanks for reading!



