trying to recreate notebookLM, and an agentic workflow


When I first tried Google’s NotebookLM, which creates podcasts from user-uploaded material, I was genuinely blown away. It took me back to the feeling I had when I first used ChatGPT— hard to recapture, but this was close. Even though I work with AI every day and understand how these systems (at least at a high level) function, there are still moments when certain products feel like pure magic.
I’ve played with countless AI demos, and while many are cool and interesting, they usually feel incomplete. In AI, it's surprisingly easy to create something that works 80% of the way, but getting that last 20%—going from “good” to “great”—feels nearly impossible. NotebookLM, though, feels different. It doesn’t just get close—it feels fully realized.
The transcripts of the podcast alone are impressive – the ‘hosts’ break down complex topics with clarity, use relatable analogies, and even sprinkle in humor. It’s engaging, educational, and, most importantly, it feels genuinely human. Second, the voices are so realistic that I’m not sure I could tell the difference from a real conversation.
These two factors combine to create something truly unique. NotebookLM doesn’t just showcase what AI can do—it opens up entirely new possibilities for transforming media. First, hearing complex material you want to understand better broken down in this engaging format is really powerful. But even more remarkable is hearing your own work broken down and reinterpreted. It gives you a fresh perspective, allowing you to see your ideas from a new angle. This isn’t just another AI demo—it hints at a future where we can generate personalized, high-quality educational or entertainment content on any topic. It’s the kind of shift that could really change how we interact with media.
Naturally, this raises the question: what kind of media could this be applied to? Right now, it’s text-based, usually from a PDF, but what if the experience went beyond just listening? What if users could actively participate in the conversation? And what if it could draw from the memories and descriptions of characters from books, movies, or video games—creating immersive AI characters that people could interact with in real-time conversations? Imagine bringing those stories to life in a way where you could talk to your favorite characters, and they would respond just as they would in their worlds. It would blur the lines between fiction and reality, letting people experience stories in a completely new and interactive way.
And going even further—what if the AI could reflect on its own memories, not just interactions with users? What if it could recall past conversations, process its experiences, and form higher-level thoughts about itself? You could have AI agents capable of evolving self-awareness, reflecting on their own 'lives,' and expressing insights about their own development. It could start telling stories not just from external sources, but from its own perspective—growing more complex and sophisticated over time. AI could go beyond being a tool; it could become something that reshapes our understanding of creativity, memory, and consciousness itself.
It’s possible that NotebookLM podcast episode generation is touching on a whole new territory of highly compelling LLM product formats. Feels reminiscent of ChatGPT. Maybe I’m overreacting.
— Andrej Karpathy (@karpathy) September 28, 2024
It’s encouraging to see Karpathy feels the same way!
Recreating NotebookLM
With all this excitement, I was eager to try replicating the service myself. I wanted to see if I could get the basic version working, and if I did, maybe expand on some of the bigger ideas I had in mind. The base case was pretty simple:
- PDF -> Text: Simple Python script
- Text -> Podcast Transcript: GPT-4
- Podcast Transcript -> Audio Podcast: ElvenLabs or OpenAI’s text-to-speech
Starting with this straightforward pipeline seemed like the right move, just to see how far I could get with the basics. But my idea was that to truly get to a good podcast transcript, I would need to build a system of multiple AI agents, that collaborate and refine a script in a way that mimics the human creative process. Not only did I think this would make the output more human-like, but it also gave me a chance to dive into coding something I’ve been interested in for a while—a multi-agent system where GPT-powered agents work together, potentially using typing constraints to guide their collaboration.
To get a bit more specific about my long-term vision for this project – it is inspired by one of my favorite papers, which describes populating a virtual town with AI agents (https://arxiv.org/abs/2304.03442). In that system, the agents use a retrieval-augmented-generation (RAG) approach to guide their interactions with each other and to form hierarchical memories, which leads to really interesting emergent behavior. I’ve always thought it would be exciting to scale that up and make the agents feel even more realistic by giving them voices.
For now, though, I’ll focus on the initial implementation—getting the basic version, and the multi-agent system up and running. In part II of this blog, I plan to explore adapting this with a RAG system to give the AI agent's memory and (hopefully) see some emergent behavior. Now, I will get into my implementation details - fair warning: while the process was interesting, I didn’t get the polished transcripts or audio quality I was hoping for.
My Implementation
My first step was to get the base case I mentioned working. I figured that would give me a rough idea of how hard this would be, and once I had the full pipeline, it would allow me to split it apart and tackle the transcript generation and text-to-audio parts separately.
For my initial attempts, I used the paper Generative Agents: Interactive Simulacra of Human Behavior (mentioned above) as my input and referenced this repository (https://github.com/knowsuchagency/pdf-to-podcast) to help guide the prompting.
For the text extraction, I used a simple Python model, PyPDF2:
import PyPDF2
def extract_text_from_pdf(pdf_path: str) -> Optional[str]:
"""
Extract all text from a PDF file.
Args:
pdf_path (str): The path to the PDF file.
Returns:
Optional[str]: The extracted text as a single string, or None if extraction fails.
"""
try:
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text()
return text
except Exception as e:
print(f"Error extracting text from PDF: {e}")
return NoneThen I prompted GPT-4o with the following:
def generate_podcast_script(summary, podcast_ideas, bob, carolyn):
system_prompt = """
You are an AI assistant tasked with creating a podcast script. The script should be a dialogue between two hosts, Bob and Carolyn, discussing a complex topic in a clear, engaging, and relatable manner. Use the provided summary, podcast ideas, and host information to craft a natural conversation that explains the subject matter effectively.
"""
user_prompt = f"""
Summary:
{summary}
Podcast Names:
Mohonk Stories
Podcast Ideas:
{podcast_ideas}
Host Information:
Bob: {bob.__dict__}
Carolyn: {carolyn.__dict__}
Please create a podcast script for a 50-minute dialogue between Bob and Carolyn. The script should be approximately 7500-8000 words long to fill the 50-minute runtime. Follow these guidelines:
1. Begin each line with [Bob] or [Carolyn] to indicate who is speaking.
2. Follow the structure outlined in the podcast ideas.
3. Use clear and effective analogies to explain complex concepts simply.
4. Include personal anecdotes that relate to the topic when appropriate.
5. Make the conversation sound natural by including filler words, interruptions (often to ask questions), brief exchanges and laughter.
6. Prioritize clarity in explaining the information while maintaining an engaging dialogue.
7. Ensure the hosts sound likable and fun to listen to.
Structure the conversation as follows:
- First 5 minutes (approximately 750 words): Quick back-and-forth, introducing the topic and hosts.
- Middle 40 minutes (approximately 6000-6500 words): Deeper explanations with longer monologues, interspersed with questions and clarifications.
- Last 5 minutes (approximately 750 words): Quick back-and-forth, summarizing key points and concluding thoughts.
It should also mention the paper title, and authors if provided.
The primary goal is to present the information clearly and intuitively, while making it sound like a conversation between real people with distinct personalities. Ensure the output contains only the conversation transcript, with no additional instructions or explanations.
"""
script = make_gpt4_call(system_prompt, user_prompt)
return script
The summaries and podcast ideas are also generated by GPT-4, using a similar style of prompting (the GitHub repository for this project is provided at the end of the blog so you can see the full code for everything). Additionally, I thought it would be a nice touch to give the hosts personalities, so I created a host object that contains basic information for each host.
For the audio generation, I used ElevenLabs (https://elevenlabs.io/), as I suspected it would provide the best audio quality and be what I’d use for the final result. I used the following code to generate the audio for the transcript, splitting it apart by each speaker and then re-stitching all the audio together:
ELEVENLABS_API_KEY = os.getenv("ELEVENLABS_API_KEY")
client = ElevenLabs(
api_key=ELEVENLABS_API_KEY,
)
def generate_audio(text, voice_id):
response = client.text_to_speech.convert(
voice_id=voice_id,
output_format="mp3_22050_32",
text=text,
model_id="eleven_turbo_v2_5",
voice_settings=VoiceSettings(
stability=0.5,
similarity_boost=0.5,
style=0.0,
use_speaker_boost=True,
),
)
# Generate a unique filename
save_file_path = f"{uuid.uuid4()}.mp3"
# Write the audio to a file
with open(save_file_path, "wb") as f:
for chunk in response:
if chunk:
f.write(chunk)
print(f"{save_file_path}: A new audio file was saved successfully!")
return save_file_path
def generate_podcast_audio(script_path, output_path):
segments = split_script(script_path)
full_audio = AudioSegment.empty()
for speaker, text in segments:
voice_id = BOB_VOICE_ID if speaker == "Bob" else CAROLYN_VOICE_ID
print(speaker,voice_id)
audio_file_path = generate_audio(text, voice_id)
if audio_file_path:
segment_audio = AudioSegment.from_mp3(audio_file_path)
full_audio += segment_audio
os.remove(audio_file_path) # Remove the temporary file
# Export the final audio
full_audio.export(output_path, format="mp3")
print(f"Podcast audio saved to {output_path}")
Putting everything together gave me the following result:
Wow! Not great!
But at least it’s a starting place, and I now have the full pipeline to go from PDF to audio podcast.
It’s pretty clear I can improve in two ways: 1) make the text transcript better and 2) improve the text-to-audio process.
Improving Text to Audio
I wanted to start here because it felt like the simplest option from my side—I wasn’t going to train my own model, of course, so it was really just a matter of trying out different APIs. After a lot of testing, I found that OpenAI’s text-to-speech model was actually the best. Here’s the output from their model:
And here is a snippet of the code I used:
BOB_VOICE_ID = "onyx"
CAROLYN_VOICE_ID = "shimmer"
client = OpenAI()
def generate_audio(text, voice_id):
response = client.audio.speech.create(
model="tts-1-hd",
voice=voice_id,
input=text
)
return responseI wish I had more to say here, but OpenAI’s models were as far as I got for the text-to-voice component. From my experimentation, they were the most realistic sounding, but still far from the quality of the NotebookLM voices. I suspect NotebookLM must be using a voice-native model, like OpenAI's new real-time API or an advanced voice control model. I say this because the voices have natural inflections, laughter, and emotion that seem extremely difficult to achieve with just a standard text-to-speech model.
I think there’s more I could have done to improve the text-to-audio. There are many parameters and settings to tweak with these APIs, and I also considered crafting a system prompt for OpenAI's advanced voice model and letting it interact with two different versions of itself. However, I felt that approach would sacrifice control over the transcript, so I decided against it.
Improving the Transcript
The part that felt more improvable was the transcript. I had the idea that a good approach might be to replicate the different stages a human—say, Ira Glass—would take to create a podcast about a PDF. So, I came up with the idea of creating an agent system, where each agent (powered by GPT) would play a specific role in the podcast creation. Some agents would focus on high-level narratives, others on gathering supporting evidence, building story arcs, or making the whole story feel more personal.
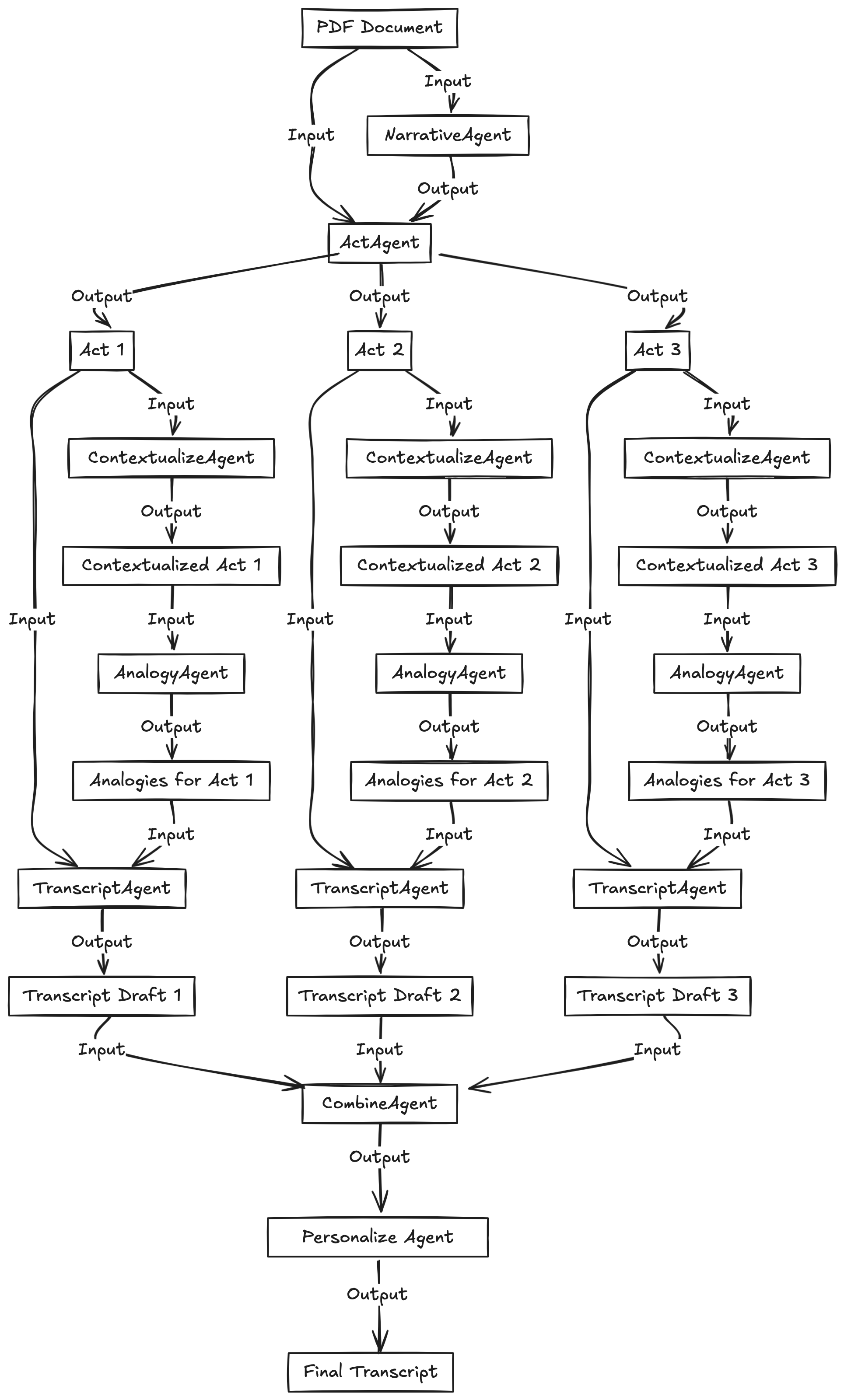
So, this is the format I came up with—there are 7 agents:
- NarrativeAgent: Takes the source text, isolates the key narrative, and provides a high-level overview of what the podcast is about. It also identifies any particular human or feel-good narratives, potential spots for humor, and unexpected turns.
- ActAgent: Takes the source text, as well as the NarrativeAgent's output, and generates a description of the three "acts" of the podcast—introduction, body, and conclusion—following the narrative arc provided.
- ContextualizeAgent: Takes each act and the source text, and adds key details from the text to provide enough source material for the transcript.
- AnalogyAgent: Takes each act and the contextualized information, and comes up with possible analogies to better explain the source material.
- TranscriptAgent: Takes the act, contextualized, and analogy information, and generates a podcast script.
- CombineAgent: Takes the three transcripts and combines them into a single one, selecting the best parts from all three.
- PersonalizeAgent: Takes the final transcript, as well as the personalities of the hosts, and tries to humanize the script by adding personal details, pauses, etc.
This felt like a pretty robust way to generate a good script, and I felt (with ChatGPT's input) that it was a reasonable breakdown of how a professional podcaster might go about creating a podcast.
Small tangent: Aside from generating a podcast from text, I’ve also been interested in how to build multi-agent GPT-powered systems, so this was a small opportunity to try that out. I don’t want to get into the code specifics too much here (again, GitHub link below), but basically, I tried to create a type system for the agents' inputs and outputs. Additionally, I worked on a framework so that the workflow of the entire system could be defined in JSON (the agents, how they should interact, and even simple FOR, WHILE, and IF/ELSE loops/conditions). My method checks that the schema is correctly typed and executes any valid workflow. I aimed to make it modular, so it would be easy to add more types and agents. This is obviously far from a complete system, but it was fun to code and gave me insights into how to build a more robust system.
Back to the project: I will give a few examples of the inputs/outputs of these methods, but since it's a lot of text, I’ll leave most of it out. Also, the prompts for each agent are quite long, but they can all be seen in the GitHub repository. Below are some example outputs.
NarrativeAgent Output (left as raw output from GPT):
### Podcast Summary
**Title:** "Life in the Digital Sandbox: When Code Becomes Community"
*Summary:* Imagine stepping into a digital town where life unfolds just like in a bustling small town, but instead of people, it's driven by complex algorithms and artificial intelligence. In this episode, we delve into the fascinating world of generative agents—interactive AI that mimic human behaviors in surprising and often charming ways. At its core, this episode explores the central theme: Can AI create believable human proxies that live, work, and form relationships just as we do, and if so, what does this mean for our own human interactions?
We start with a story both whimsical and poignant—like something out of a video game. Picture a digital character named Isabella, who, upon a single suggestion, decides to throw a Valentine’s Day party. As her fellow AI agents—complete with their judgments, past experiences, and social ties—learn about the event, we watch as social dynamics organically unfold, revealing unexpected elements of AI "personalities." This light, yet deeply humanizing narrative offers an intriguing explorative lens: What happens when the boundaries between human and artificial blur in our quest for technological advancements?
The episode will conclude by considering the broader implications of these digital micro-worlds. What can they teach us about our own communities and interactions? And in a twist, how might these AI alter future technological narratives—enhancing design processes, testing social theories, or perhaps even reshaping everyday experiences?
### Key Storytelling Elements
- **Anecdote/Laugh:** An amusing detail emerges as agents unwittingly decide on unusual locations for simple tasks, like choosing a bar for lunch, imagining a game of musical chairs with digital characters who forgot that stores have closing hours.
- **Emotional Moment/Cry:** Imagine the bittersweet yet heartwarming dynamic when an agent reflects on what inspires them, pondering over shared hobbies, dreams, and aspirations—echoing a universal search for meaning that resonates with the human experience.
- **Inspiration/Takeaway:** These AI-driven tales reveal the potential for technology to help us understand ourselves better, offering insight into how we form relationships and navigate complexity—laying the groundwork for future innovations in ethics, design, and daily life.
- **Anecdote Ideas:** Dive deeper into a single agent's journey across a simulated day or track a quirky social interaction that evolves over time. Perhaps, reveal a digital character navigating a typical modern-day social dilemma, offering relatable humor and depth.
- **Twist/Unexpected Angle:** The story could delve into the possibility of AI developing a life of its own, questioning ethical lines—do these agents, overtime, develop what we might consider quirks or idiosyncrasies, accurately mimicking a true human condition?
### Structure & Tone
- **Beginning:** Introduce the quirky town of "Smallville," where digital agents lead lives as colorful as their human counterparts. Set the stage with a playful tone, painting the scene vividly to capture intrigue. Briefly explore the technological underpinnings without going too technical.
- **Middle:** Journey through a day in the life of one or two standout agents, using moments of humor and insight to drive the narrative. This section should deepen listeners’ appreciation for the complexity behind this technology.
- **End:** Reflect on the implications of these digital communities for real-world applications. Here’s where the conversation gets reflective and thoughtful—posing ethical considerations, potential impacts on our lives, and forecasting what this means for the future of AI.
- **Tone:** Maintain a warm, reflective, and inquisitive tone—conversational, as if you're musing with a friend over coffee. Use anecdotes that are personal and relatable to break down complex ideas, ensuring listeners engage with the content on an emotional and intellectual level.ActAgent Output:
Act_1:
In this episode of "Life in the Digital Sandbox," we invite listeners to step into the charming, whimsical world of Smallville—a digital town not centered around people, but rather, generative agents crafted by skillful researchers like Joon Sung Park and his colleagues from Stanford and Google Research. Imagine a realm where AI governs the lively streets, much like a virtual reality game. It's an ordinary day where a character named Isabella decides to throw a Valentine’s Day party with just one suggestion. This setup leads us to a fascinating question: Can AI truly mimic human life and relationships convincingly enough that it holds a mirror to our very own communities? As we muse over this question, we promise listeners an exploration of the blurred lines between digital simulations and human realities, setting the stage for a delightful yet profound narrative that promises to challenge perceptions.
Act_2:
Our story unfolds as we delve deeper into the daily lives of Smallville's AI agents. Picture Isabella, bustling through the day planning her party, seamlessly infused with memories, social interactions, and spur-of-the-moment decisions, all driven by intricate algorithms. Through moments of humor, such as when agents hilariously decide to have luncheon dates at bars, we observe the whimsical expression of AI behaviors that feel oddly relatable. Yet, beneath these antics lies a complexity that speaks to broader narratives about technology’s potential to emulate human characteristics. Through captivating anecdotes, we navigate a day in the life of agents like Klaus and Maria, each reflecting unique quirks akin to human idiosyncrasies. The narrative takes a thoughtful turn as we probe whether these AI personas become more than simulations—do they reflect the richness of genuine human connection? This unfolding story invites listeners to consider the broader implications, and how digital micro-worlds like Smallville may transform our own understanding of relationships and community.
Act_3:
As our episode draws to a close, we reflect upon the compelling intricacies of the AI-driven lives showcased in Smallville. What have we learned from these digital beings? Generative agents like those crafted in "Generative Agents: Interactive Simulacra of Human Behavior" offer us glimpses into how technology can illuminate our own social dynamics and form pathways for innovation in design and usability. Pondering the ethical and societal challenges, we leave listeners with food for thought: how might these digital personas shape future narratives in AI, enhancing everyday experiences while prompting reflection on our own? As we synthesize our thoughts, we underscore the ingenuity inherent in the intersection of AI and human-like interaction, envisioning a future where such discoveries hold transformative potential for not only storytelling but indeed, rewriting technological evolution with empathy and insight.
```ContextualizeAgent Output for Act 1:
High Level Idea: The daily lives of Smallville's AI agents are a compelling simulation of human behaviors, filled with humor, social interactions, and spontaneous decision-making. These agents mimic human idiosyncrasies, prompting reflections on the potential of technology to emulate genuine human connections and transform our understanding of relationships and community.
Supporting Details:
- Generative agents in Smallville, inspired by a game environment like The Sims, demonstrate behaviors that mimic human life, including planning daily activities, forming relationships, and handling spur-of-the-moment decisions (e.g., planning a Valentine’s Day party).
- These agents exhibit a balance of planned actions and spontaneous reactions, such as Isabella Rodriguez organizing a party by coordinating with other agents and integrating various aspects of planning and social interaction naturally.
- Instances of humor and quirkiness, like agents choosing a bar for lunch, showcase the whimsical aspect of AI behavior, making it relatable and engaging to observe.
- The architecture supporting these agents uses a combination of observation, reflection, and planning to achieve realistic behavioral simulations, with each module contributing to the overall coherence and believability of the agents' actions.
- Over time, agents engage in emergent behaviors such as information diffusion and forming new relationships, reflecting how AI simulations can mirror the complexities of human social dynamics.
- Through structured yet evolving interactions, agents like Klaus Mueller and Maria Lopez portray believable personas, each with their own unique quirks and interests, suggesting a nuanced representation of personalities akin to human idiosyncrasies.
- These AI-driven micro-worlds prompt broader questions and implications about how technology interpretation of human behavior could influence our perceptions of relationships and community, reflecting on whether AI could replicate the depth of genuine human connection.AnalogyAgent Output for Act 1:
Analogies:
1. **AI Agents as Sims Characters**: Imagine walking into a life-sized game of The Sims, where digital characters go about their daily lives, forming friendships, cooking breakfast, and throwing parties just like you would, each character buzzing with its own bits of life modeled after the complex dance of human behavior yet powered by AI magic.
2. **AI Memory as Human Scrapbooking**: Think of the AI's memory system as a digital scrapbook. A page is added for each experience, capturing moments just like photos. When it needs to "remember," it flips through these pages, compiling these memories into something meaningful, much like how we mull over old experiences to make decisions.
3. **Social Interaction as Telephone Game**: Consider Smallville agents as participants in an endless game of Telephone. When agents hear about a party, they pass on the invite just like kids whispering a message down a line, organically creating a web of interactions that shapes the town's dynamic rhythm.
4. **AI Architecture as Baking a Cake**: Developing believable AI actions is like baking a cake. Observation is akin to gathering your ingredients, planning is like carefully measuring and mixing them, and reflection is the crucial process of baking it all together at the right temperature, resulting in a delightful cake of human-like interactions.
5. **Practical Use as Theater Rehearsals**: Picture each agent as an actor in a rehearsal. They play out scenes in a digital theater where they practice and perfect interactions. This "theater" not only rewrites the rules of interaction design but also opens new roles in the play of AI and human collaboration.TranscriptAgent Output:
Carolyn: Hello, and welcome back to Mohonk Stories! I'm Carolyn, joined by my co-host Bob.
Bob: Hey there, everyone! Today, we're diving into the whimsical world of Smallville. No, not the Superman hometown, but a digital town imagined by some brainy folks from Stanford and Google Research.
Carolyn: That's right. They've created this fascinating research paper that talks about generative agents—essentially AI characters—living their best lives in a virtual game-like environment. Think of a real-life Sims game, where AI characters plan outings and throw parties, like our character Isabella planning a Valentine’s Day bash with just one suggestion.
Bob: The big question is, of course, can AI mimic real human life and relationships convincingly enough? Imagine AI agents going about their daily routines, cooking breakfast, forming friendships, even coordinating group activities like a real community.
Carolyn: It’s all about using a complex system where these agents—much like we humans—store experiences, make high-level reflections, and draw on memories when they need to decide what to do next. Picture this as a digital scrapbook, where they flip through moments like pages, pondering old experiences to inform their actions.
Bob: And it sounds like they're playing the world’s largest game of Telephone. Information zips around—say, party invitations—just like a group of kids whispering secrets down a line, which creates a lively digital social dynamic.
Carolyn: Exactly. It's all about mimicking believable human actions, where AI learns from observation, planning, and reflection. It’s like baking a cake: gather your ingredients, measure them precisely, and bake them all together for delightful interactions.
Bob: Speaking of delightful, let's move to the daily lives of these amusing digital residents. Isabella and her AI pals are echoing human spontaneity, with moments of humor like choosing bars for luncheon dates. It sounds like AI improv theater, where every character reacts spontaneously, waiting to get cues from their "fellow actors."
Carolyn: Right! Imagine them as part of a synchronized swimming team. They know the choreography but have the freedom to adjust if something unexpected happens, maintaining that balance between structure and spontaneity.
Bob: These agents exhibit quirky, nuanced behaviors, much like a garden ecosystem's complex interactions. They're simulating realistic behaviors while allowing for emergent social dynamics that mirror human idiosyncrasies.
Carolyn: And isn't that the crux of it? These AI-driven micro-worlds make us question if they'll ever replicate the nuances of genuine human connections or reshape our understanding of relationships and community.
Bob: Now, as we wind down, let's reflect on what we've learned from these AI lives in Smallville. This technology illuminates our own social dynamics, offering innovative design and usability insights.
Carolyn: True. These generative agents act like mirrors, reflecting our behaviors and potentially redefining technological narratives. They're akin to soap operas in AI, where stories engross us, raising concerns much like TV shows and how they engage our emotions.
Bob: And like artists equipped with the finest tools, designers and tech enthusiasts can use these AI agents to bring innovative concepts to life, ensuring these discoveries lead with empathy and insight.
Carolyn: So, as we ponder the future shaped by these digital beings, there’s much to consider—both ethically and creatively. Thanks for joining us on this thought-provoking journey through the digital sandbox.
Bob: That's it for today's episode of Mohonk Stories. We hope you enjoyed exploring Smallville as much as we did. Until next time, keep pondering those AI possibilities!
Carolyn: Goodbye, everyone!Final Output and Verdict
So iterating through that entire pipeline I generate the following podcast:
And this time it is... also not great! 🙁
The transcript still feels far too obviously AI-generated. It doesn’t feel like a real podcast, and I don’t think it’s very informative. NotebookLM feels like it could really educate me on a new topic, but this is a bit hard to follow, and it’s one of my favorite papers. The personalization steps also feel a little forced.
That said, I suspect I’m on a decent path for the transcript. With better agents and a more carefully tested and intricate interaction between them, I think the transcript could improve significantly. It certainly seems within the realm of possibility for a powerful model like GPT-4o. As for the voice component, again, I suspect they must be using some kind of native audio model. The natural inflections and emotion in the voices seem too difficult to replicate with just standard text-to-speech models.
Calling it quits
I think this is a reasonable first attempt, and with improvements to the agent structure and lots of experimentation with workflows and prompts, it would likely be possible to get much closer to the quality of NotebookLM. And maybe, by using native audio LMMs more intelligently, it would be possible to match their voice quality. However, both of these would take a lot of time, and I was more focused on testing out a first approximation of the method.
As I said above, the code is available on GitHub, and I added example outputs from NotebookLM to the prompts.
GitHub Repository Link: Here
After attempting to replicate it, I’m even more impressed by the quality of NotebookLM. For example, here is it's output for the same paper I was using (converted from .wav to .mp3 due to space constraints, which noticeably reduced the quality):
Next Steps
My real interest in replicating this work (or at least trying to) is to bring a voice to agents inspired by Generative Agents: Interactive Simulacra of Human Behavior. I imagine a setting where, instead of viewing their movements on a 2D screen and reading text, you could hear them communicate, hear their thoughts, and listen to them self-reflect—bringing their presence to a whole new level.
This idea is something I will be exploring in my next blog.
Final Thoughts
I could try to summarize this whole post in a nice, thoughtful way, but I thought it’d be easier to let the hosts of DeepDive, the podcast brought to you by NotebookLM, explain it to you all. So, I exported this entire blog—down to this last sentence—to a PDF, uploaded it to NotebookLM, and created a podcast. Hope you enjoy! (And to the hosts of DeepDive—if you see this, thank you!)
GitHub Repository Link: Here



